OpenAI用26分钟再次震撼世界!
新模型GPT-4o语音水平接近人类,科幻正在成真 。
北京时间5月14日凌晨,OpenAI再迎重磅更新,虽然不是AI搜索,也不是GPT-5.而是发布了新旗舰模型GPT-4o,但也足以让业内震撼。
在此次OpenAI 仅有26分钟的春季发布会中,OpenAI首席技术官穆里·穆拉提(Muri Murati)宣布推出名为GPT-4o的新旗舰生成式AI模型,其集文本音频视觉于一身,能力全新升级。
此前不少爆料提到,OpenAI将推出AI搜索,与谷歌搜索竞争,从而增强ChatGPT的功能并开拓新市场,并称这款产品将在谷歌本周的开发者大会前推出。
不过,OpenAI CEO山姆·奥特曼对此否认,其表示,“不是 GPT-5.也不是搜索引擎,但我们一直在努力开发一些我们认为人们会喜欢的新东西!对我来说就像魔法一样。”
GPT-4o显然就是奥特曼所说的“像魔法一样”的新东西。GPT-4o中的o就是Omni,其是拉丁语词根,意思是全面、全能,奥特曼称其“最好的模型”,并免费开放。
发布新旗舰模型GPT-4o,语音能力接近人类
穆里・穆拉蒂在发布会上提到,GPT-4o 提供与GPT-4同等水平的智能,但进一步改进了GPT-4在文本、视觉以及音频方面的能力。
“GPT-4o是迈向更自然的人机交互的一步——它支持文本、音频和图像的任意组合作为输入,并生成文本、音频和图像的任意组合输出。”OpenA在官网上介绍称。
根据传统基准测试,GPT-4o在文本、推理和编码智能方面实现了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉功能上达到新的水平。如在文本方面,GPT-4o在多项测试上超过 GPT-4 Turbo或与其持平,并超过谷歌、Anthropic和Meta目前最强模型。
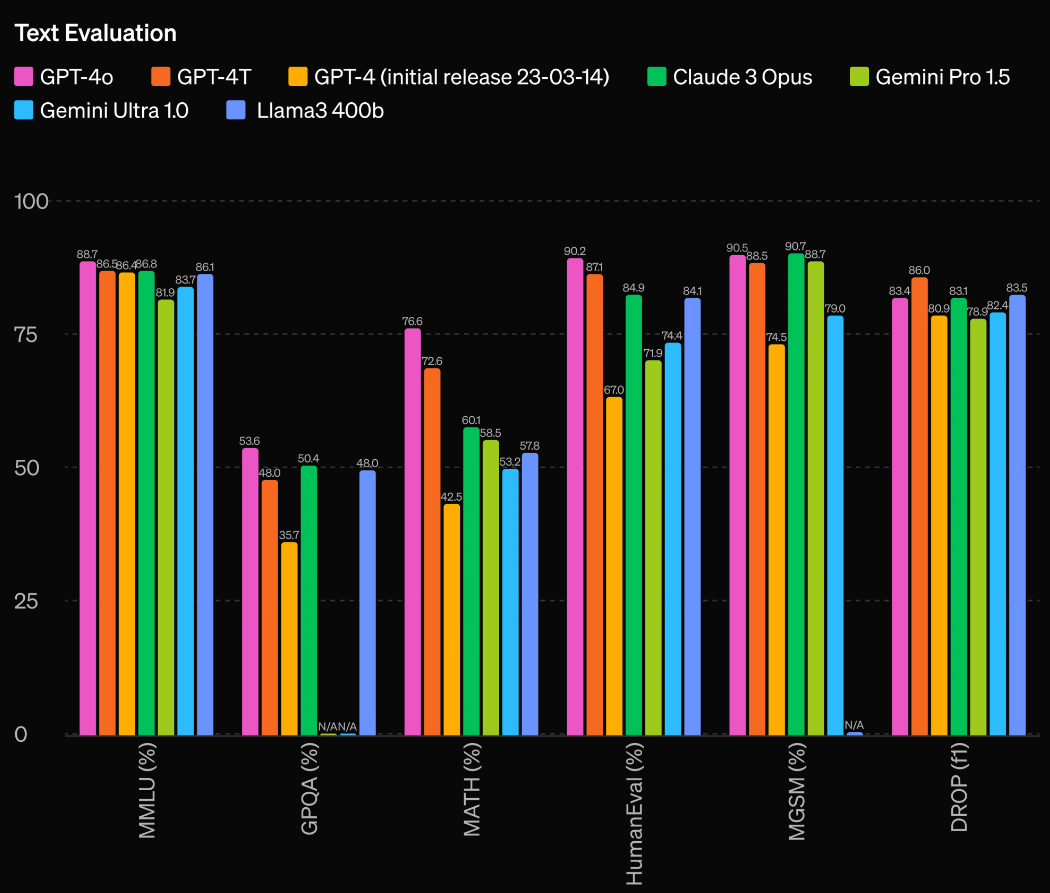
在音频语音识别和翻译方面,GPT-4o相比OpenAI自己开发的语音模式Whisper-v3均显著提高,尤其是在语音翻译方面树立了新的最先进水平。同时,在视觉理解评估中,GPT-4o也全面超过GPT-4.以及谷歌和Anthropic的最先进模式。
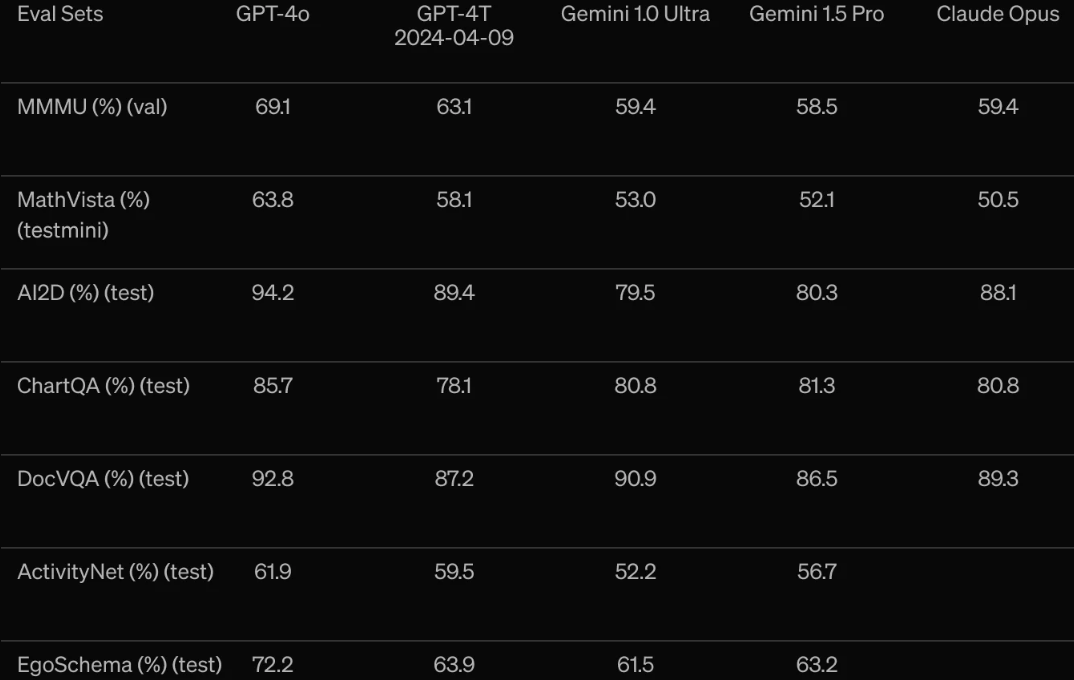
OpenAI 此前的旗舰模型GPT-4.可以处理由图像和文本混合的信息,并能完成从图像中提取文字或描述图像内容等任务,GPT-4o则在此基础上进一步增强了语音处理能力。
据穆里・穆拉蒂介绍,GPT-4o的运行速度将大大提升,最大亮点在于其语音交互模式采用了新技术,从而使得人们可以用麦克风与 ChatGPT 交谈。
OpenAI 介绍到,在GPT-4o之前,使用语音模式与ChatGPT对话,平均延迟为2.8秒(GPT-3.5)和5.4秒(GPT-4)。其中的语音模式由三个独立模型组成:一个简单模型将音频转录为文本,GPT-3.5或GPT-4接收文本并输出文本,第三个简单模型将该文本转换回音频。
但这个过程会导致GPT-4丢失大量信息——它无法直接观察音调、多个说话者或背景噪音,也无法生成笑声、音乐或表达情感。为此GPT-4o在跨文本、视觉和音频方面端到端地训练了一个新模型,意味着所有输入和输出都由同一神经网络处理,从而提高了相应速度和推理能力。
“GPT-4o可以在短至232毫秒的时间内响应音频输入,平均为320毫秒,这与人类在对话中的响应时间相似。”OpenAI 称,与现有模型相比,GPT-4o在视觉和音频理解方面尤其出色,不仅可以将语音转换为文本,还具备先进的音频理解能力,理解和标记音频,如能感受到呼吸和情感,并可以控制其声音,比如发出兴奋、舒缓或者机器人的声音。
“OpenAI 一直致力于让用户通过语音与 ChatGPT 进行交流,仿佛与真人对话一般,但之前的版本由于延迟问题,严重影响了对话的沉浸感。GPT-4o 则采用了全新的技术,让聊天机器人对话的响应速度大幅提升。”穆里・穆拉蒂表示。
此外,在文字、图片和语音之外,GPT-4o 还支持打AI视频电话,其可以看到你所有的表情和情绪变化,还可让它来解答各种问题,比如在线解数学题,甚至还可以一起逗狗。
根据发布会上OpenAI使用 GPT-4o进行语音对话的演示,在提问结束后,GPT-4o几乎可以即时回应,并通过文本转语音功能进行朗读,且对话比较自然逼真。

它还可以根据要求调整说话语气或声音,夸张戏剧、冰冷机械都不在话下,比如在它看到写着“我爱ChatGPT”的纸条时,会跟小女生一样害羞地尖叫起来。发布会还展示了GPT-4o唱歌和数学方面的能力,可以指导求解简单的方程。
此外,OpenAI 还发布了桌面版ChatGPT和新的用户界面。“我们认识到这些模型正变得越来越复杂,但我们希望用户与人工智能模型的交互体验能够更加自然、轻松,让用户可以将注意力完全集中在与模型的协作上,而无需在意界面本身。”穆里・穆拉蒂表示。
奥特曼称GPT-4o是最好模型,免费开放使用
此次发布会中,奥特曼并未现身。不过,他在推特发文称“GPT-4o是我们有史以来最好的模型”,并提到了科幻电影《Her》。
这部十年前的电影,讲述了作家西奥多爱上电脑操作系统里女声的故事,这个名为“萨曼莎”的姑娘有着性感嗓音,并且风趣幽默、善解人意。GPT-4o在语音视频上的交互能力,让科幻正在加速走向现实,还有网友称《流浪地球中》的MOSS诞生了。
同时,奥特曼还专门发了一篇博客,称GPT-4o提供新的语音和视频模式,是其用过的最好的计算机界面。“感觉就像电影里的人工智能一样,我仍然有点惊讶它是真的。事实证明,达到人类水平的响应时间和表达能力是一个巨大的变化。”
他认为,最初的ChatGPT显示了语言界面的可能性,而这个新事物给人的感觉有本质上的不同,它快速、智能、有趣、自然且有帮助。
“对我来说,与计算机交谈从来都不是很自然的事情,现在确实如此。但当我们有添加个性化、访问你的信息、代表你采取行动的能力等时,我确实可以看到一个令人兴奋的未来,我们能够使用计算机做比以往更多的事情。”奥特曼表示。
值得一提的是,不同于此前OpenAI在推出模型新版本都会对特定付费用户开放,这次则决定GPT-4o向用户免费开放。
从今天开始,GPT-4o的文本和图像功能会在ChatGPT中推出,免费提供GPT-4o,并向Plus 用户提供高达5倍的速率限制,还将在未来几周内在ChatGPT Plus 中推出新版本的语音模式GPT-4o alpha。
此外,开发人员也已经可以在API 中访问GPT-4o。与GPT-4 Turbo 相比,GPT-4o速度提高2倍,价格降低一半,速率限制提高5倍,并计划未来几周内在API中向部分合作伙伴推出对GPT-4o新音频和视频功能的支持。
OpenAI研究员William Fedus表示,“GPT-4o是我们最先进的新前沿模型,也是世界上最好的模型,而且可以在 ChatGPT中免费使用,这对于前沿模型来说是前所未有的。”
奥特曼则在博客中强调称,在创立OpenAI 时,最初构想是要创造人工智能并利用它造福世界,而OpenAI使命的一个关键是将非常强大的AI工具免费(或以优惠的价格)提供给人们。
“我们是一家企业,会有很多收费的东西,这将帮助我们向数十亿人提供免费、出色的人工智能服务。”但奥特曼表示,“我非常自豪我们在ChatGPT中免费提供了世界上最好的模型,没有广告或类似的东西。”
不过,OpenAI表示,GPT-4o是其第一个结合多模式的模型,是突破深度学习界限的最新成果,在朝着实用性的方向发展,但仍然只是浅尝辄止地探索该模型的功能。
同时,GPT-4o虽然通过过滤数据、模型细化、创建新的安全系统、与外部专家沟通等,为语音输出提供技术和交互上的安全防护,但还是会带来新的安全风险,且仍存在一些局限性,如有时会答非所问或给出错误信息等。
OpenAI表示,在接下来的几周和几个月里,将致力于推进技术基础设施、培训可用性以及发布其它模式所需的安全性,并希望得到反馈继续改进模型。